
.png)
TL;DR
- The success of enterprise AI projects boils down to search and retrieval. In order to deliver production-grade AI apps, developers need tools that efficiently access data across distributed systems.
- Modern AI apps demand hybrid search across structured, unstructured, and vectorized data. Today’s fragmented stacks introduce latency, complexity, and risk.
- Spice solves the search challenge with its hybrid SQL search functionality that natively combines keyword/text search, relational filters, and vector similarity in one query.
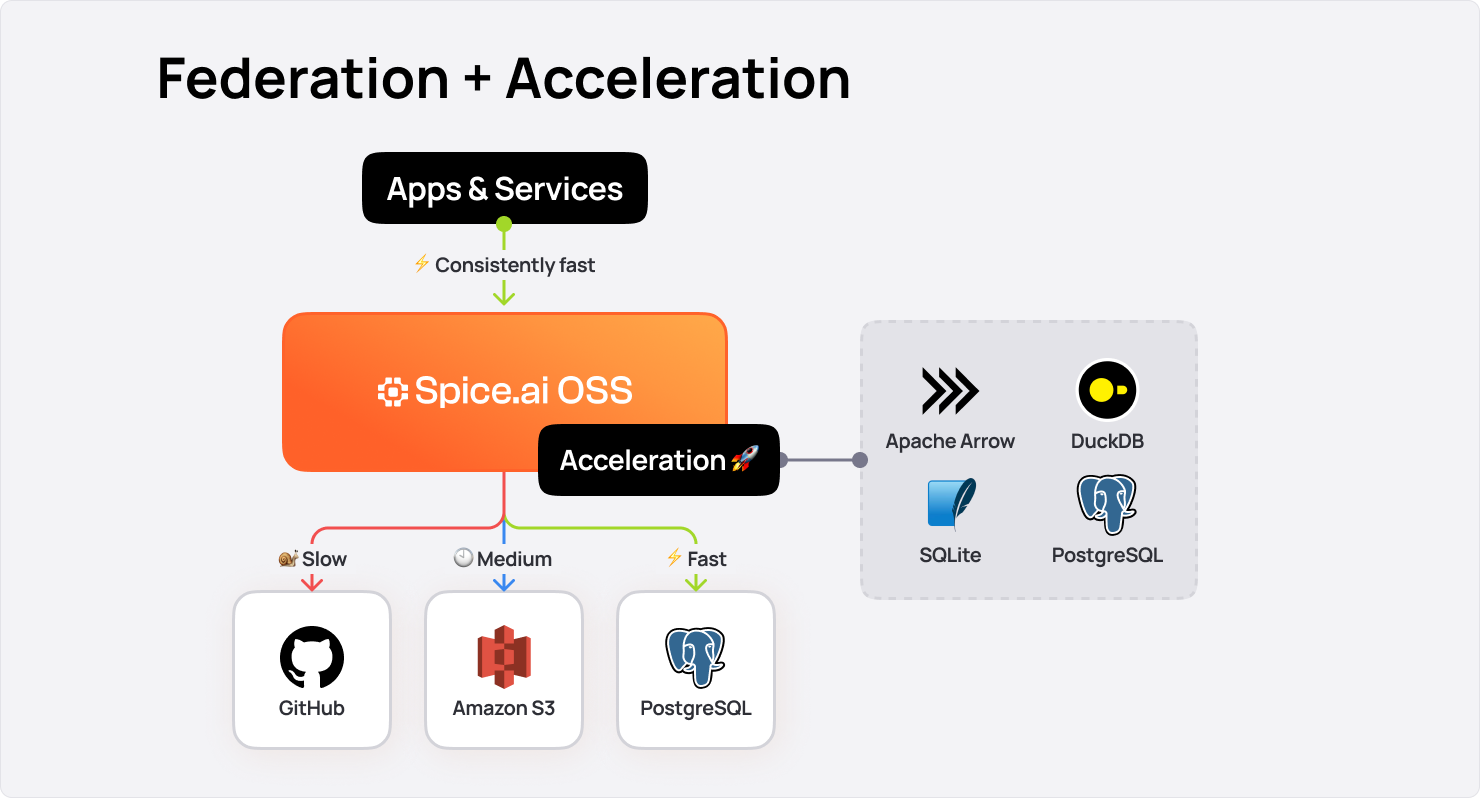
- Hybrid search alone isn’t enough. To deliver production-grade AI, it must be combined with query federation, acceleration, and inference. Spice AI unifies query, search, and inference in a single, open-source runtime that queries data in place—across databases, warehouses, and object stores like S3—while accelerating the slowest layers.
- Spice operationalizes object stores for AI, making S3, ADLS, and GCS fast enough for semantic and hybrid search without duplicating data into specialized systems.
Show Me the (Data)!
It's well established (and maybe even trite) to say that enterprises are going all-in on artificial intelligence, with more than $40 billion directed toward generative AI projects in recent years.
The initial results have been underwhelming. A recent study from the Massachusetts Institute of Technology’s NANDA initiative concluded that despite the enormous allocation of capital, 95% of enterprises have seen no measurable ROI from their AI initiatives. Only 5% of custom AI pilots ever make it to production, and just a fraction of those deliver meaningful business outcomes.
AI models are only as effective as the context (data) they can retrieve, but enterprise data is scattered across transactional databases, analytical platforms, object stores, and countless other data sources. To accommodate this fragmentation, enterprises have historically relied on fragile ETL pipelines, complex integrations, and siloed point solutions like search engines or vector databases. Each new layer introduces latency, operational overhead, and security risk. The proof is reflected in the results of MIT’s study: instead of accelerating innovation, these pipelines are slowing it down. Enterprise-grade AI applications fail not necessarily due to the underlying models or because they can’t be built, but because they can’t reliably access the data they need.
The Search Imperative
Enterprise AI is fundamentally a search and retrieval problem. Applications and agents must be able to reach across structured and unstructured data, apply both exact filters and semantic search, and return the right context in milliseconds.
This requires three retrieval paradigms:
- Exact filtering: Exact matches and filters on structured, relational, or semi-structured data for fields, timestamps, and metadata.
- Keyword search: Keyword discovery in unstructured text like documents and logs, ranked on term frequency and proximity.
- Semantic search: Vector embeddings for semantic-based similarity across any data type, from tables to narratives, beyond literal terms.
Large organizations have worked around this problem by standing up multiple specialized systems: a relational database for queries, a search engine for text, a vector store for embeddings, etc. They then build pipelines to keep those systems in sync, often resulting in complexity and fragility.
Meanwhile, object storage offerings like Amazon S3, Azure Blob, and Google Cloud Storage serve as the system of record for massive volumes of enterprise data - and thus excellent data sources for AI applications. However, they were never designed for low-latency retrieval. Even with the emergence of open formats like Parquet, Iceberg, and Delta, raw performance lags far behind what modern AI applications require.
This ultimately leaves enterprise developers in a catch-22: either they duplicate data into faster but more expensive systems, or they accept latency that makes real-time AI use cases impractical.
An Emerging Data Convergence
Three industry shifts are now reshaping this landscape and enabling a new generation of applications:
- Object stores are becoming queryable. With Iceberg, Delta, Hudi, and now S3 Vectors, they are evolving into platforms for active workloads, not just cold storage.
- AI workloads are inherently hybrid. They need structured data for grounding, unstructured text for context, and embeddings for semantics. No single monolithic database can meet these needs.
- Enterprises are under pressure to simplify. The cost of maintaining separate systems for query, search, and vector retrieval is too high - in dollars, in complexity, and in security risk.
Taken together, these shifts mandate a new substrate that unifies search, query federation, and inference across all enterprise data.
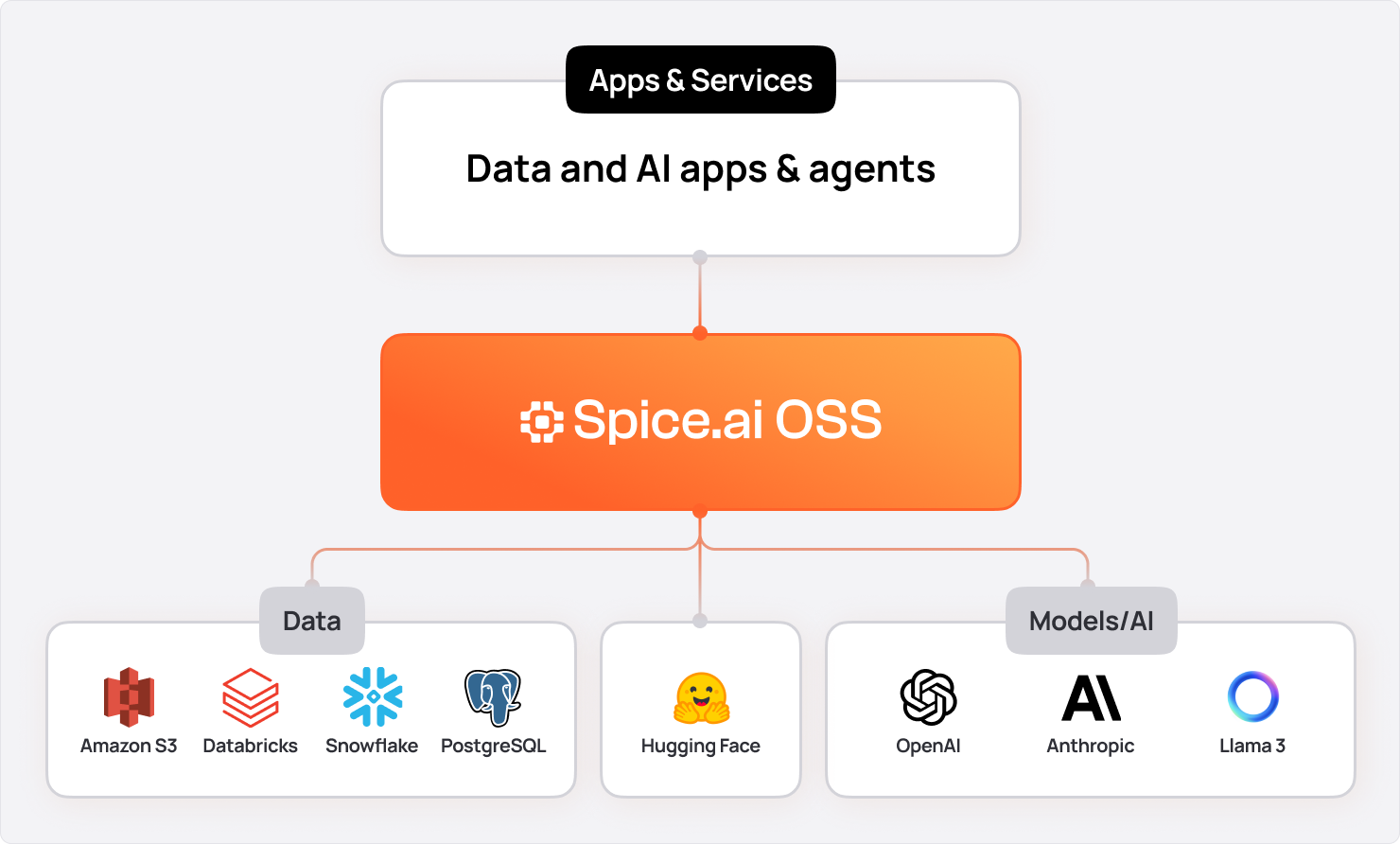
Spice.ai: From Fragmented Data to Unified Intelligence
Spice.ai was purpose-built to address this challenge, offering a data and AI platform that combines hybrid search (vector, full-text, and keyword) with query federation, acceleration, and LLM inference in one engine.
Where other vendors solve a piece of the problem, Spice addresses the full lifecycle. For developers, this means one query interface replacing three. A hybrid search against structured, unstructured, and vectorized data can be expressed in a single SQL statement, with Spice abstracting all of the orchestration. Applications that once required stitching together a handful of different systems can now be built against one, and results that once took minutes arrive in milliseconds.
Take the below Spice query as an example. One SQL combines vector search, full-text search, temporal and lexical filtering.
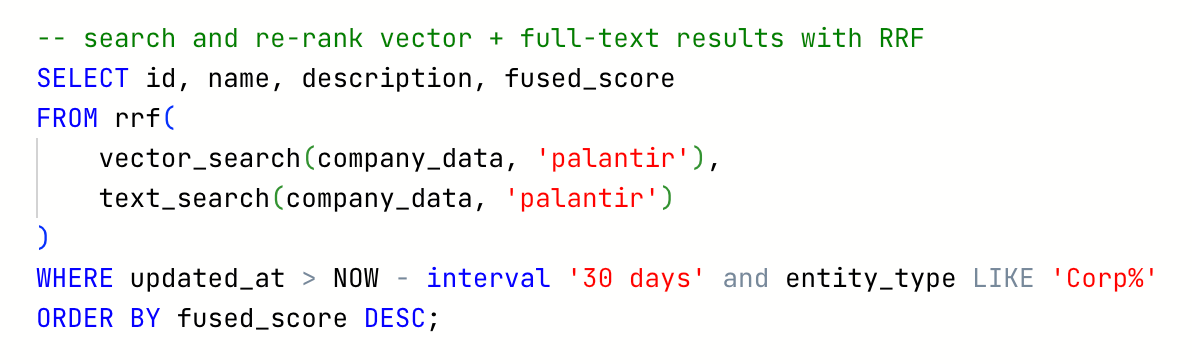
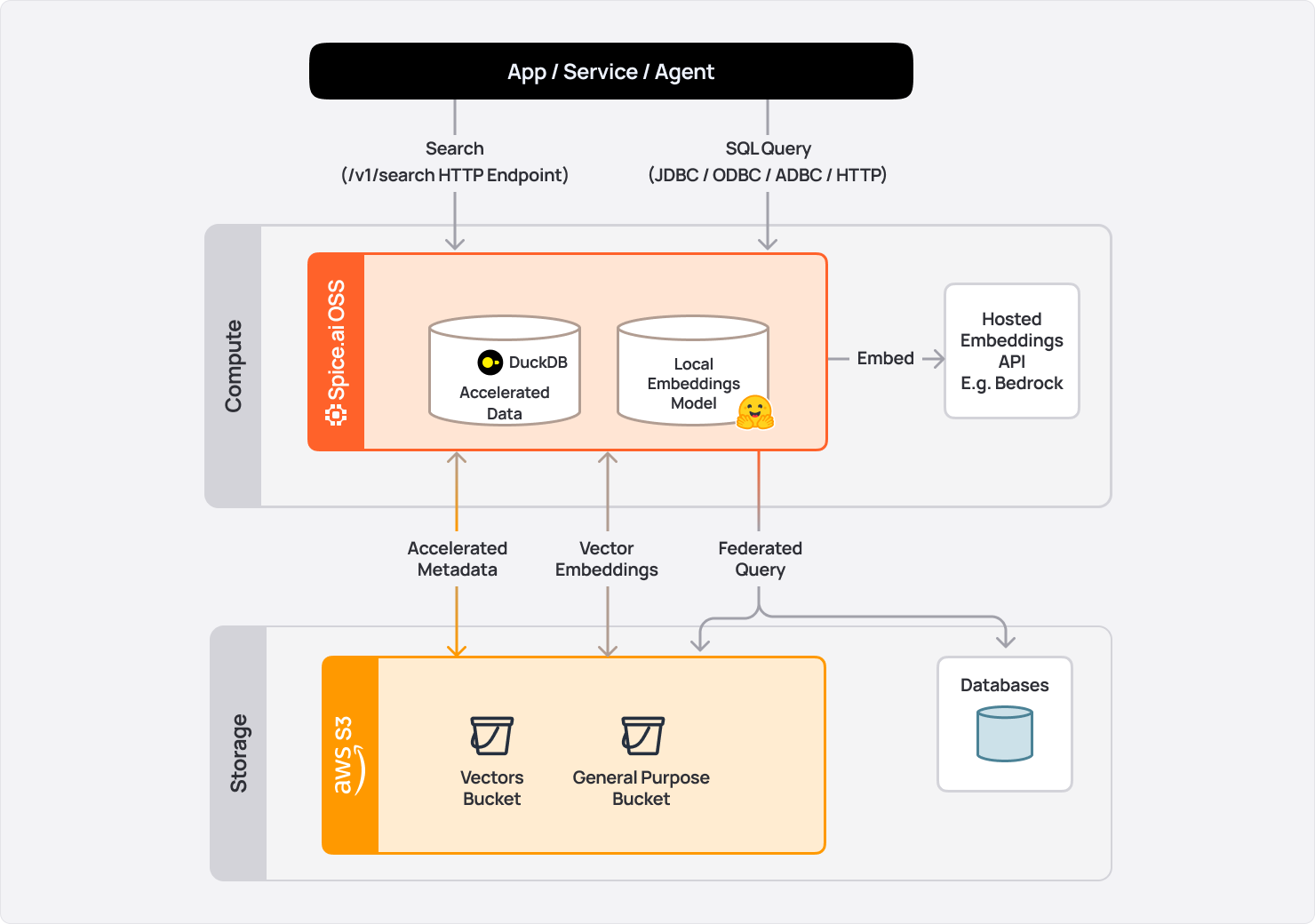
But search alone isn’t enough. Enterprise AI applications also need low latency retrieval across data systems when integrating with LLMs. That’s why Spice pairs its search engine with query federation, acceleration, and AI inference in a single, deploy-anywhere runtime. Instead of moving data, Spice queries it where it resides - across OLTP databases, OLAP warehouses, and object stores like S3 - while accelerating the slowest layers through caching and materialization for sub-second access. This makes it possible to serve data and AI-powered experiences directly from your existing systems - securely, at low latency, and without costly re-engineering.
In turn, this architecture turns object stores from passive archives into active, AI-ready data layers. With the introduction of native support for Amazon S3 Vectors, Spice can even create, store, and query embeddings natively in S3, making semantic search as accessible as traditional text search or object retrieval.
Enterprises eliminate the operational drag of ETL pipelines and duplicated data stores, security improves because sensitive databases are never directly exposed to AI agents, and perhaps most importantly, AI apps that failed due to lack of reliable retrieval are now viable.
Architecture Overview
Spice’s lightweight compute engine is designed to integrate directly into your application stack and is built on a fully open-source foundation. It embeds the DataFusion SQL query engine, supports over 35 open-source connectors, and can locally materialize data for acceleration using DuckDB, SQLite, or PostgreSQL.
Core components of Spice:
- Search & Retrieval. Vector, hybrid, and full-text search across structured and unstructured data.
- Federated SQL Engine. Execute queries across disparate data sources.
- Acceleration Engine. Materialize and pre-cache data for millisecond access.
- LLM Inference. Load models locally or use as a router to hosted AI platforms like OpenAI, Anthropic, Bedrock, or NVIDIA NIM.
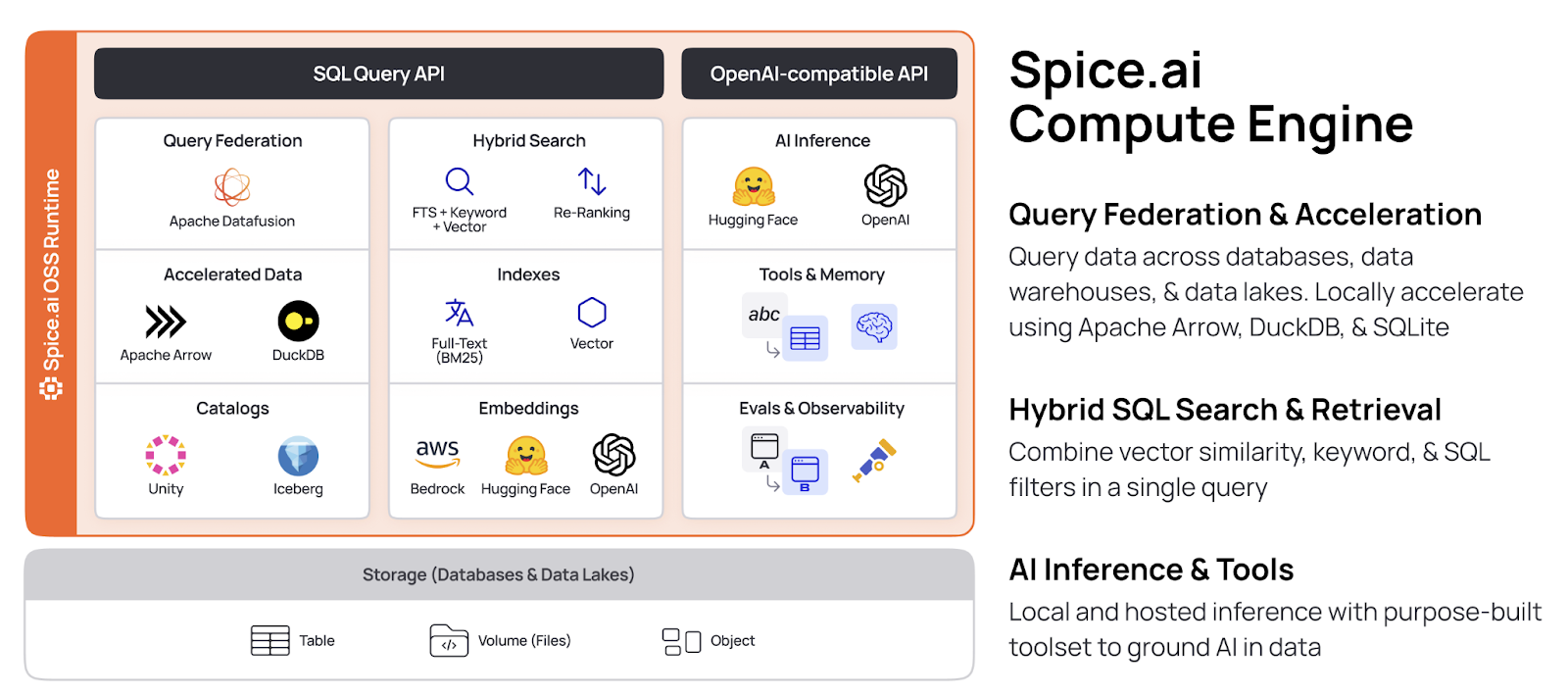
Spice can be deployed:
- As a sidecar: Co-located with your application for ultra-low latency.
- As a shared service: Centralized deployment serving multiple applications.
- At the edge: Serve data and AI capabilities as close as possible to the user.
- In the cloud: Fully-managed via the Spice.ai Cloud Platform.
This deployment flexibility ensures Spice fits to your application architecture and compliance requirements.
Applications Built on Spice
Whether you’re powering a RAG-enabled customer service bot, an internal AI agent, or a high-throughput transactional API, the foundational challenge is the same: getting fast, secure access to the right data at the right time.
Spice solves that challenge once, and lets you deploy the same solution for every workload. Spice enables three primary categories of applications: AI Apps, RAG Apps, and Data Apps.
- AI Apps
AI models are only as good as the context they can access. As discussed, most enterprise AI efforts fail because retrieval is too slow, incomplete, or insecure.
Key benefits of using Spice for AI Apps include:
- Ground LLMs in enterprise data without moving data into separate stores.
- Retrieve structured and unstructured data in real time, with hybrid SQL search.
- Keep sensitive systems secure by acting as a containerized execution layer, so AI agents never query a production database directly.
- RAG (Retrieval-Augmented Generation) Apps
Traditional RAG is powerful but fragile - performance, relevance, and freshness/veracity all depend on the retrieval layer.
Key benefits of using Spice for RAG Apps include:
- Unified retrieval that spans transactional, analytical, and object store data sources.
- Low-latency query performance for interactive AI experiences.
- Dynamic materializations that refresh context automatically, ensuring AI agents always have the latest data without paying a tax on re-ingestion.
3. Data Apps
Modern data applications often need to unify data from multiple disparate systems, deliver low-latency results, and scale globally without constant ETL jobs or manual integrations.
Key benefits of using Spice for Data Apps include:
- Federated SQL queries across OLTP, OLAP, and object store systems without pre-processing or data duplication.
- Accelerated database and object store queries to sub-second speeds, enabling a “Database CDN” model where working datasets are staged close to the application.
- Real-time updates via Change Data Capture (CDC), intervals, or event triggers, so apps never query stale data.
The Path Forward with Spice
The boundaries between operational databases, analytics, and object stores are dissolving, and AI applications demand all three together in real-time.
Traditional approaches, anchored on moving and transforming data between systems, can’t keep up with these demands. Spice makes search and retrieval reliable, fast, and unified - turning fragmented data into a single searchable layer. With sub-second access to transactional, analytical, and object data, enterprises can finally deliver intelligent applications at scale.
Getting Started
Spice is open source (Apache 2.0) and can be installed in less than a minute on macOS, Linux, or Windows:
- Explore the open source docs and blog for cookbooks, integration examples.
- Visit the getting started guide
- Explore the 70+ cookbooks
- Try Spice.ai Cloud for a fully managed deployment and get started for free.
Interested in working with Spice AI or looking to learn a little more about the work we do? We are always looking for our next big challenge. Book an introductory call via our Calendly. Take a deeper look at our enterprise offerings by visiting Spice.ai.
.png)
.png)
.png)








